AI At Scale
Over the past years, large deep learning language models (LM) with billions of parameters have improved the state-of-the-art in nearly every DL application. In particular there are many progress in natural language processing (NLP) field.
Massive deep learning language models (LM), such as BERT and GPT-2, with billions of parameters learned from essentially all the text published on the internet, have improved the state of the art on nearly every downstream natural language processing (NLP) task, including question answering, conversational agents, and document understanding among others.
Microsoft Project Turing is introducing Turing Natural Language Generation (T-NLG), the largest model ever published at 17 billion parameters.
Turing model for natural language generation (NLG), the largest model ever published at 17 billion parameters, outperforming the state of the art on a variety of language modeling benchmarks while accomplishing numerous practical tasks such as summarization and question answering.
Any model with billions parameters cannot fit into a single GPU (even one with 32GB of memory like NVIDIA VT100), so the model itself must be parallelized, or broken into pieces, across multiple GPUs. (Model parallelism not only data parallelism).
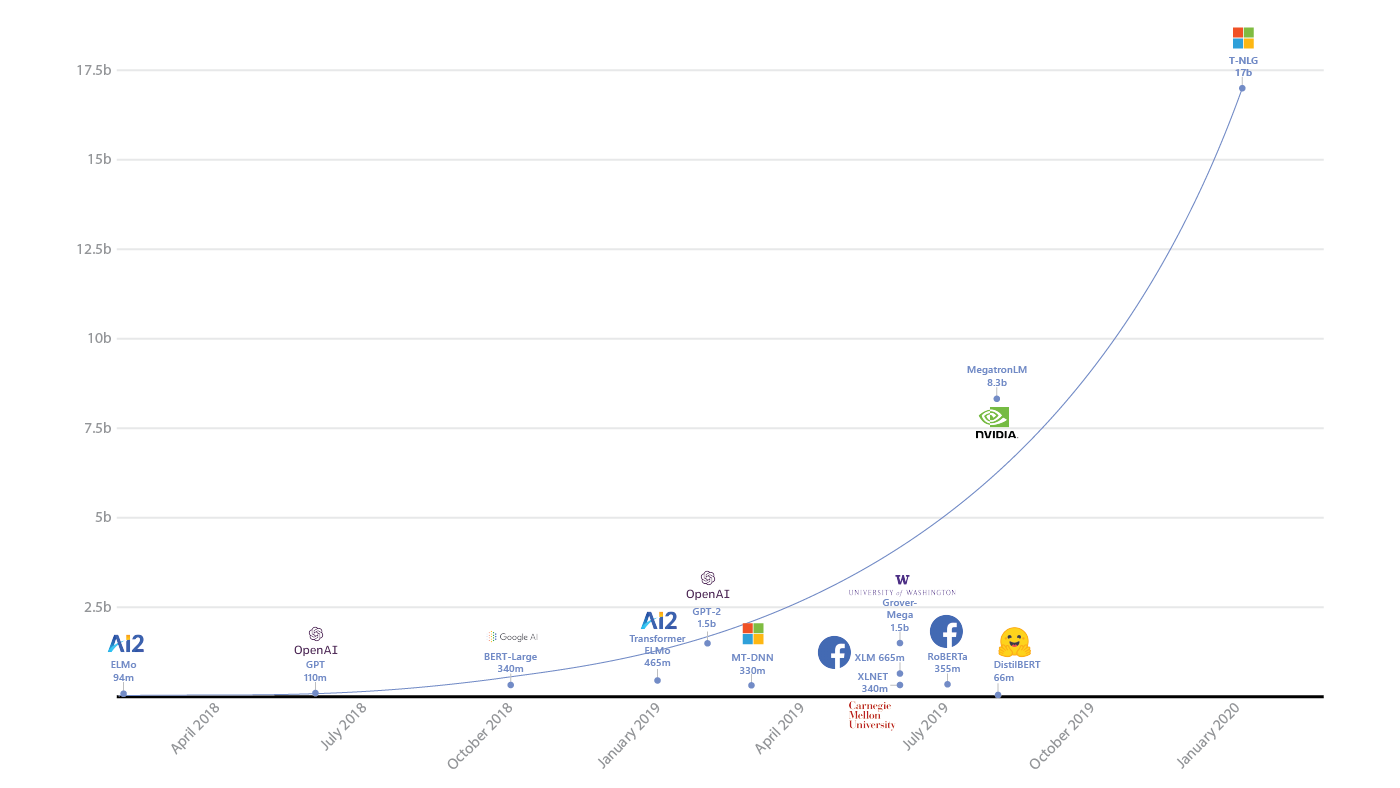
However, for very large models beyond a billion parameters, the memory on a single GPU is not enough to fit the model along with the parameters needed for training, requiring model parallelism to split the parameters across multiple GPUs. Several approaches to model parallelism exist, but they are difficult to use, either because they rely on custom compilers, or because they scale poorly or require changes to the optimizer.