Azure Machine Learning
Azure Machine Learning is a cloud-based platform for building and operating machine learning solutions in Azure. It includes a wide range of features and capabilities that help data scientists prepare data, train models, publish predictive services, and monitor their usage. Most importantly, it helps data scientists increase their efficiency by automating many of the time-consuming tasks associated with training models; and it enables them to use cloud-based compute resources that scale effectively to handle large volumes of data while incurring costs only when actually used.
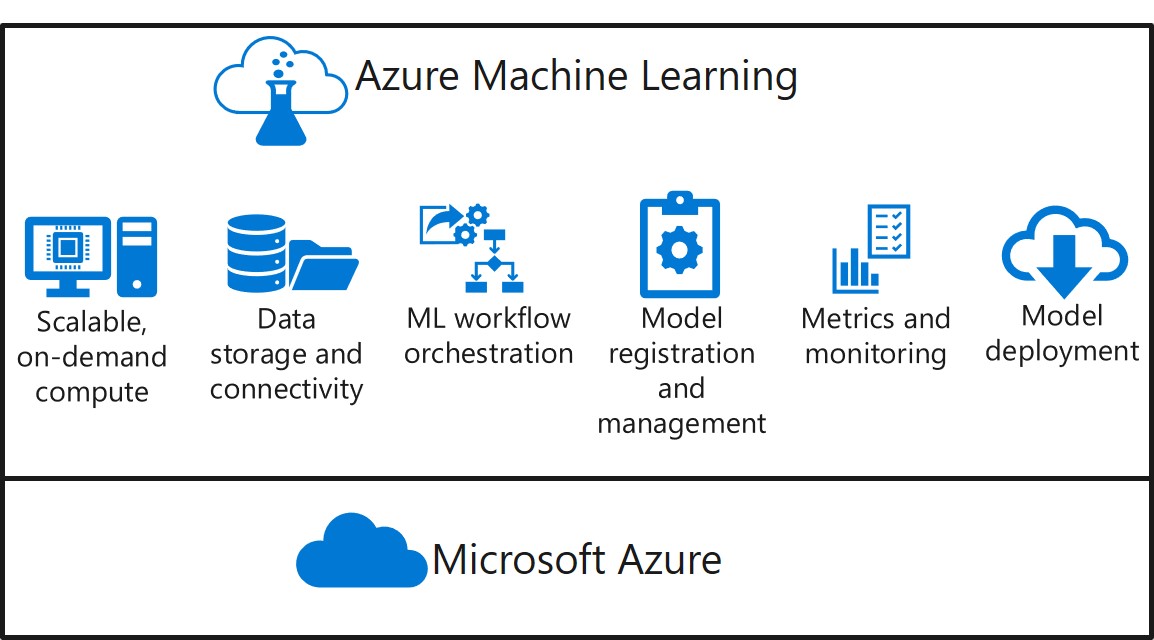
Built on the Microsoft Azure cloud platform, Azure Machine Learning enables you to manage:
Scalable on-demand compute for machine learning workloads. Data storage and connectivity to ingest data from a wide range sources. Machine learning workflow orchestration to automate model training, deployment, and management processes. Model registration and management, so you can track multiple versions of models and the data on which they were trained. Metrics and monitoring for training experiments, datasets, and published services. Model deployment for real-time and batch inferencing.
Azure MAchine Learning Workspace
To use Azure Machine Learning, you create a workspace in your Azure subscription. You can then use this workspace to manage data, compute resources, code, models, and other artifacts related to your machine learning workloads.
A workspace is a context for the experiments, data, compute targets, and other assets associated with a machine learning workload.
The assets in a workspace include:
- Compute targets for development, training, and deployment.
- Data for experimentation and model training.
- Notebooks containing shared code and documentation.
- Experiments, including run history with logged metrics and outputs.
- Pipelines that define orchestrated multi-step processes.
- Models that you have trained.
Workspaces as Azure Resources
Workspaces are Azure resources, and as such they are defined within a resource group in an Azure subscription, along with other related Azure resources that are required to support the workspace.

The Azure resources created alongside a workspace include:
- A storage account - used to store files used by the workspace as well as data for experiments and model training.
- An Application Insights instance, used to monitor predictive services in the workspace.
- An Azure Key Vault instance, used to manage secrets such as authentication keys and credentials used by the workspace.
- A container registry, created as-needed to manage containers for deployed models.
For each one of the resources listed above there are associated costs even is the workspace in not used. So you must delete the worspace id you do not want to consume your credits1.
Compute Resources
There are four kinds of compute resource you can create:
- Compute Instances: Development workstations that data scientists can use to work with data and models.
- Compute Clusters: Scalable clusters of virtual machines for on-demand processing of experiment code.
- Inference Clusters: Deployment targets for predictive services that use your trained models.
- Attached Compute: Links to existing Azure compute resources, such as Virtual Machines or Azure Databricks clusters.
Creating a Workspace
You can create a workspace in any of the following ways:
- In the Microsoft Azure portal, create a new Machine Learning resource, specifying the subscription, resource group and workspace name.
- Use the Azure Machine Learning Python SDK to run code that creates a workspace.
For example, the following code creates a workspace named aml-workspace (assuming the Azure ML SDK for Python is installed and a valid subscription ID is specified):
from azureml.core import Workspace
ws = Workspace.create(name='aml-workspace',
subscription_id='123456-abc-123...',
resource_group='aml-resources',
create_resource_group=True,
location='eastus'
)
- Use the Azure Command Line Interface (CLI) with the Azure Machine Learning CLI extension.
For example, you could use the following command (which assumes a resource group named aml-resources has already been created):
az ml workspace create -w 'aml-workspace' -g 'aml-resources'
Azure Machine Learning studio
Azure Machine Learning studio is a web-based tool for managing an Azure Machine Learning workspace.
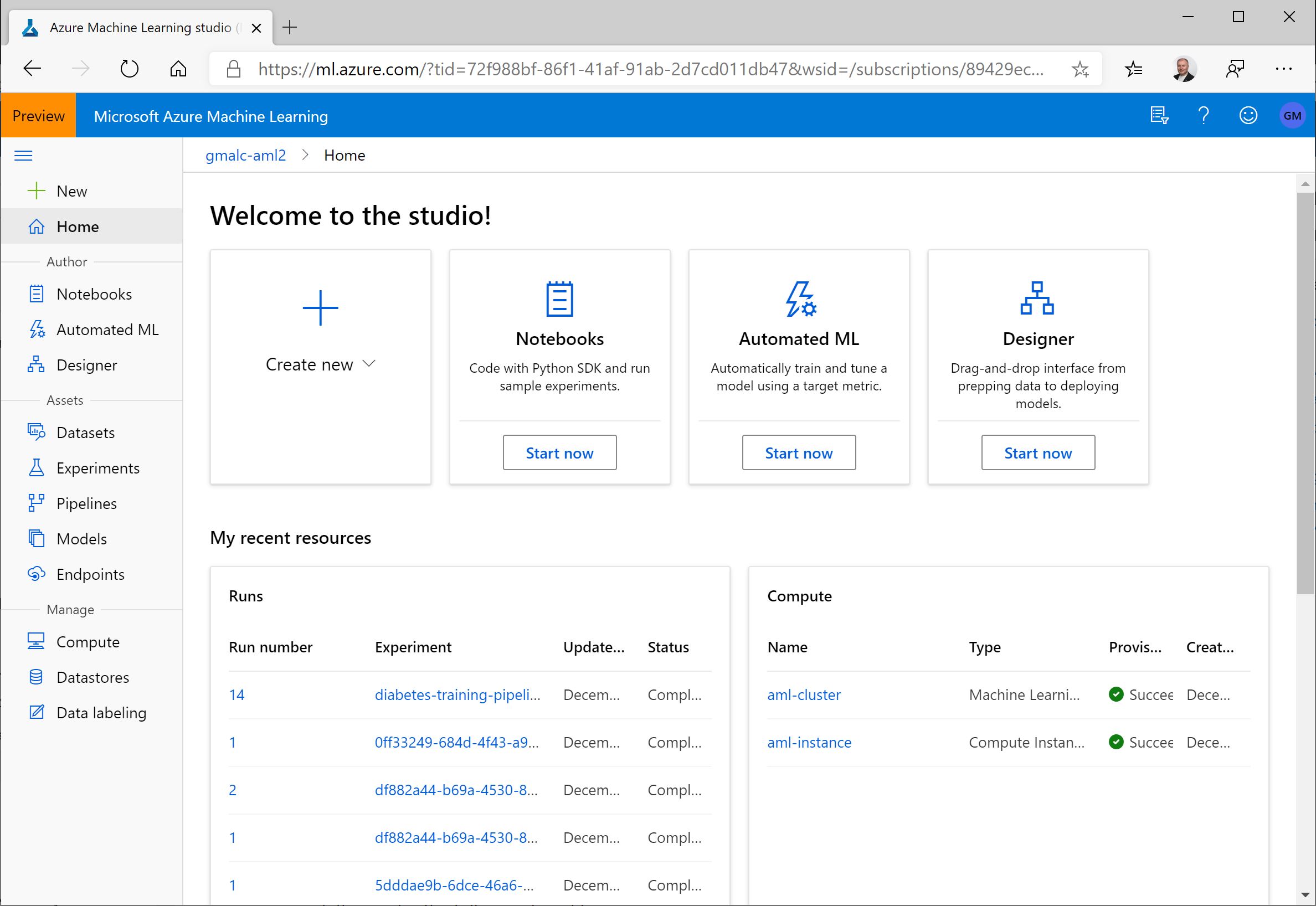
To use Azure Machine Learning studio, use a a web browser to navigate to https://ml.azure.com and sign in using credentials associated with your Azure subscription. You can then select the subscription and workspace you want to manage.
A previously released tool named Azure Machine Learning Studio provided a free service for drag and drop machine learning model development. The studio interface for the Azure Machine Learning service includes this capability in the designer tool, as well as other workspace asset management capabilities. The old tool still availale as “Azure Machine Learning Studio Classic”.
Azure Machine Learning Studio Classic miss many features present in Azure Machine Learning Worspace, but there is 100% free service plan available.
The Azure Machine Learning SDK
While graphical interfaces like Azure Machine Learning studio make it easy to create and manage machine learning assets, it is often advantageous to use a code-based approach to managing resources.
Azure Machine Learning provides software development kits (SDKs) for Python and R, which you can use to create, manage, and use assets in an Azure Machine Learning workspace.
Installing the Azure Machine Learning SDK for Python
You can install the Azure Machine Learning SDK for Python by using the pip package management utility.
pip install azureml-sdk[notebooks,automl,explain]
For more information about installing the Azure Machine Learning SDK for Python, see the SDK documentation.
Retrieving and Viewing Logged Metrics
You can view the metrics logged by an experiment run in Azure Machine Learning studio or by using the RunDetails widget in a notebook, as shown here:
from azureml.widgets import RunDetails
RunDetails(run).show()
import json
# Get logged metrics
metrics = run.get_metrics()
print(json.dumps(metrics, indent=2))
Experiment Output Files
In addition to logging metrics, an experiment can generate output files. Often these are trained machine learning models, but you can save any sort of file and make it available as an output of your experiment run. The output files of an experiment are saved in its outputs folder.
run.upload_file(name='outputs/sample.csv', path_or_stream='./sample.csv')
When running an experiment in a remote compute context, any files written to the outputs folder in the compute context are automatically uploaded to the run’s outputs folder when the run completes.
Whichever approach you use to run your experiment, you can retrieve a list of output files from the Run object like this:
import json
files = run.get_file_names()
print(json.dumps(files, indent=2))
Running a Script as an Experiment
To run a script as an experiment, you must define a script configuration that defines the script to be run and the Python environment in which to run it. This is implemented by using a ScriptRunConfig object.
For example, the following code could be used to run an experiment based on a script in the experiment_files folder
from azureml.core import Experiment, ScriptRunConfig
# Create a script config
script_config = ScriptRunConfig(source_directory=experiment_folder,
script='experiment.py')
# submit the experiment
experiment = Experiment(workspace = ws, name = 'my-experiment')
run = experiment.submit(config=script_config)
run.wait_for_completion(show_output=True)
An experiment script (such as experiment.py) is just a Python code file that contains the code you want to run in the experiment. To access the experiment run context (which is needed to log metrics) the script must import the azureml.core.Run class and call its get_context method. The script can then use the run context to log metrics, upload files, and complete the experiment.
from azureml.core import Run
import pandas as pd
import matplotlib.pyplot as plt
import os
# Get the experiment run context
run = Run.get_context()
# load the diabetes dataset
data = pd.read_csv('data.csv')
# Count the rows and log the result
row_count = (len(data))
run.log('observations', row_count)
# Save a sample of the data
os.makedirs('outputs', exist_ok=True)
data.sample(100).to_csv("outputs/sample.csv", index=False, header=True)
# Complete the run
run.complete()